
Escalation management is what happens when a customer's problem is too big, too technical, or too urgent for the first person they talk to.When a customer's problem is too big, too technical, or too urgent for the first person they talk to, you need a plan. That plan is escalation management. It’s not about just bumping a ticket up the ladder; it’s a formal process that ensures the right expert sees the right issue at the right time.
Without this system, even small problems can snowball into full-blown crises.
What Is Escalation Management, Really?
Think of your support team like a hospital's emergency room. A nurse at the front desk can handle a simple cut or a common cold. But for a severe injury, the patient is immediately rushed to a specialist. Your escalation process should work the same way, quickly triaging issues and routing them to the person best equipped to solve them.
This isn’t just a nice-to-have for customer service. It’s a critical business function that protects your reputation and keeps customers loyal. Without a clear escalation path, tough problems get stuck, customers get furious, and your team is left putting out fires all day.
The True Cost of Poor Escalation
When escalations go wrong—or don't happen at all—the damage spreads quickly. Customers don't just get frustrated; they walk away for good. The numbers don't lie.
Industry studies show that around 85% of customer dissatisfaction comes from unresolved issues, which are often the result of a broken escalation process. On the flip side, companies with clear escalation rules see up to a 40% reduction in the time it takes to fix problems. You can dig into more data on how these practices improve support at Supportman.io.
This data makes it obvious: good escalation management isn't an expense, it's an investment. It directly impacts how many customers you keep, how efficiently your team works, and how healthy your bottom line is.
The Foundation of a Strong Escalation System
A solid escalation system isn't just a single document; it’s built on a few core pillars that work together. These components give your team the structure they need to handle pressure and act with confidence. Let's break down what those pillars look like.
The four pillars are the bedrock of any successful escalation strategy. Getting them right means creating a process that is both reliable for your team and reassuring for your customers.
The Four Pillars of Effective Escalation Management
| Pillar | Description | Impact on Business |
|---|---|---|
| Clear Triggers | Pre-set conditions that automatically signal an escalation is needed. This could be a missed deadline, a highly technical question, or an angry customer. | Prevents issues from lingering and ensures critical problems get immediate attention. |
| Defined Tiers | A structured support hierarchy where each level has specific responsibilities. For example, Tier 1 for basic questions, Tier 2 for technical troubleshooting. | Clarifies ownership, streamlines handoffs, and ensures problems are handled by someone with the right skills. |
| Service Level Agreements (SLAs) | Firm commitments on response and resolution times for each tier. These act as promises to your customers and benchmarks for your team. | Creates accountability, manages customer expectations, and provides measurable performance goals. |
| Communication Protocols | Standardized rules for how information is shared between agents and how the customer is kept in the loop during an escalation. | Ensures smooth transitions, prevents information from getting lost, and keeps the customer feeling supported. |
By weaving these elements into a cohesive strategy, you turn chaotic escalations into a predictable and controlled process. For a practical example, check out our sample escalation procedure to see how these pieces fit together. This foundation not only empowers your agents but also gives your customers peace of mind.
How We Got to Modern Escalation Management
To really get why escalation management works the way it does today, it helps to look back at its roots. Surprisingly, the whole concept didn't start in a modern call center or tech company. It was born on the factory floor.
Think about it. Early manufacturing pioneers were constantly dealing with a familiar challenge: how do you fix a problem without bringing the entire operation to a grinding halt? A single broken machine or a bad part could throw a wrench in the whole assembly line. This constant pressure forced them to get systematic about spotting, flagging, and fixing issues with real urgency.
From Assembly Lines to IT Helpdesks
A huge breakthrough came from the Toyota Production System. They introduced a principle called Jidoka, which roughly translates to "automation with a human touch." It gave any worker on the line the power to stop everything if they saw something wrong. This was a game-changer. Instead of just letting a mistake move down the line, the problem was tackled right then and there by the right person.
This simple idea planted the seeds for what we now call escalation management:
- Immediate Detection: Catching the problem the moment it appears.
- Empowered Frontline: Trusting the first person on the scene to sound the alarm.
- Rapid Response: Pulling in the right expert to solve the problem at its source.
This shift prevented tiny mistakes from snowballing into huge, expensive disasters. It was proof that having a structured way to handle problems beats just hoping for the best.
The historical roots of escalation management systems can be traced back to early 20th-century process management and quality control approaches. These historical developments laid the foundation for modern escalation methodologies that emphasize data-driven, continuous improvement, and cross-functional collaboration. You can explore more on these foundational business process guidelines.
The Digital Transformation of Escalation
When businesses went digital, those same factory-floor principles were adapted for a new kind of assembly line: the IT service desk. The problems changed from broken machinery to software bugs and server crashes, but the need for a disciplined response was exactly the same.
Frameworks like the Information Technology Infrastructure Library (ITIL) took these ideas and built a rulebook for the tech world. This is where we got concepts that are now staples in customer support, like tiered support levels, Service Level Agreements (SLAs), and formal incident management.
The language evolved—"defects" became "tickets," and "engineers" became "Tier 3 support"—but the underlying logic never changed. The Tier 1 agent who escalates a tricky bug to a developer is doing the same thing as the factory worker who stopped the line. It just goes to show that escalation management is simply good problem-solving, refined over a century of practice.
Building Your Escalation Framework from Scratch
A great escalation process doesn't just appear out of thin air—it’s carefully built. Think of it like creating the emergency response plan for your entire support team. Without a clear blueprint, your agents are left to guess during a crisis, which is a perfect recipe for inconsistent service and frustrated customers.
Putting a framework together from scratch might feel like a huge task, but it really boils down to answering three simple questions: when should we escalate, who should handle it, and how fast do we need to fix it? When you have clear, deliberate answers to these questions, you give your team the confidence and a straightforward path to follow when the pressure is on.
The whole point is to move from reactive chaos to proactive control. This flowchart lays out the basic journey an escalated ticket should take, from the moment it's identified to its final resolution.
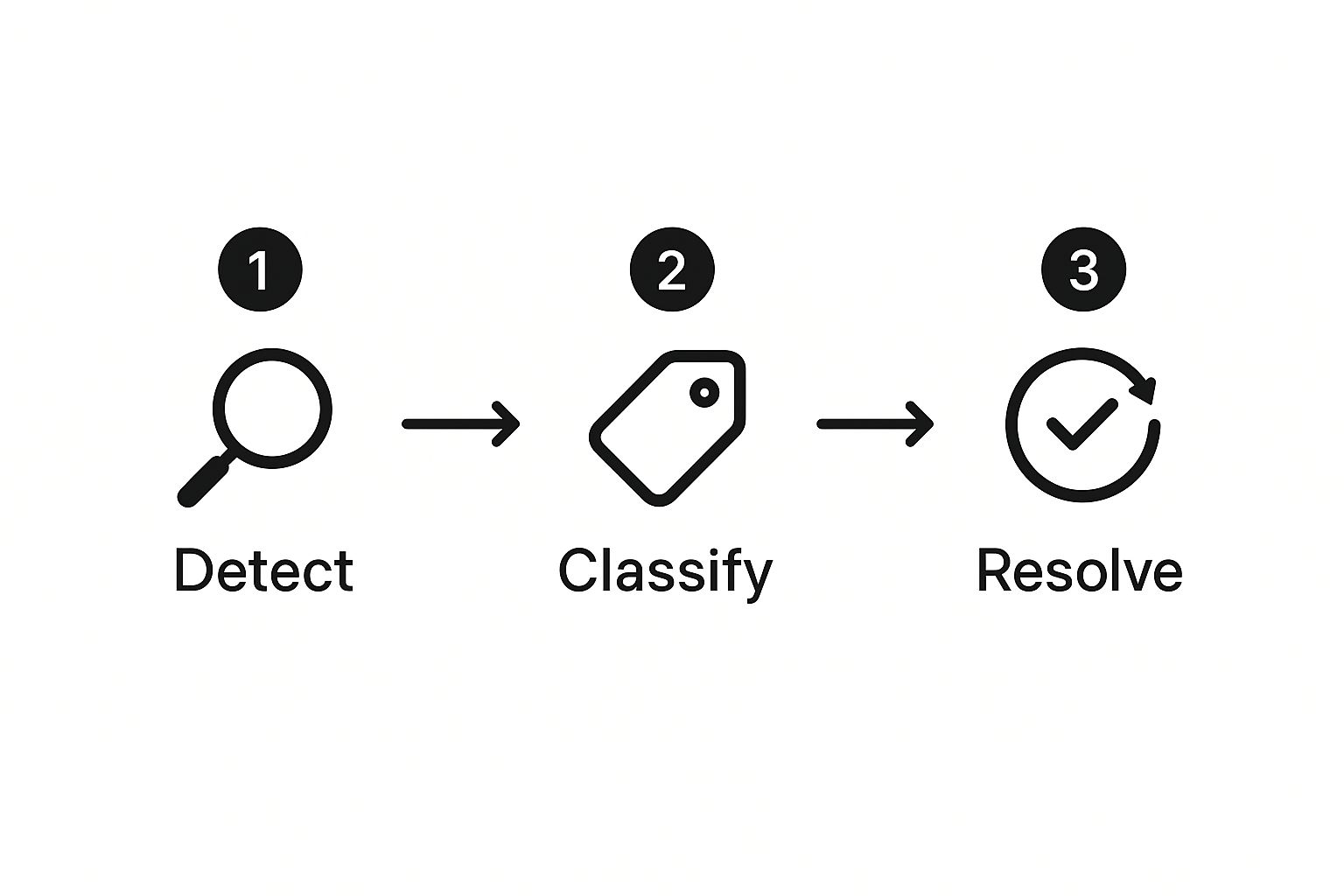
As you can see, every escalation should follow a set path: detect, classify, and resolve. This structured approach ensures nothing gets missed and every issue is handled the same way, every time.
H3: Defining Your Escalation Triggers
First things first, you need to define your escalation triggers. These are the specific, non-negotiable rules that tell an agent, "This problem is no longer yours to solve alone." Vague guidelines like "escalate when it gets too hard" are useless. You need concrete rules.
Your triggers should be a mix of objective facts and subjective judgment. For instance, a widespread system outage is an obvious, objective trigger. A customer threatening to take legal action is another crystal-clear signal.
Here are a few common types of escalation triggers:
- Technical Complexity: The issue requires skills or system access the current agent doesn't have (like needing to pull a server log or query a database).
- SLA Breach: A ticket is about to miss its promised response or resolution time. With 93% of customer service teams saying customer expectations are higher than ever, hitting these deadlines is critical.
- Customer Sentiment: The customer is incredibly unhappy, angry, or has repeatedly asked to speak with a manager.
- High-Value Impact: The problem is affecting a VIP client, a huge number of users, or has serious financial consequences.
By writing these triggers down, you take the guesswork out of the equation. Your Tier 1 agents will know exactly when to pass the baton, making sure problems don’t get stuck at the wrong level.
H3: Structuring Your Support Tiers
Once a trigger is pulled, where does the issue go? This is where support tiers come into play. Tiers are simply the different levels of your support team, each with more advanced expertise and authority. A well-defined tier system creates a smooth handoff to the right person.
Most companies find a simple, three-tiered system works best:
- Tier 1 (Frontline Support): These are your generalists. They handle the bulk of incoming requests, answer common questions, and fix basic problems. Their main job is to solve what they can and accurately escalate what they can't.
- Tier 2 (Technical Support): This team has deeper product knowledge and technical skills. They jump on complex troubleshooting, investigate bugs, and handle issues that Tier 1 couldn't resolve.
- Tier 3 (Expert Support): This is your highest level of support, often made up of engineers, developers, or product managers. They handle critical bugs, system-level failures, and problems that require code changes or highly specialized knowledge.
The key here is clarity. Everyone on your support team needs to know exactly who is in each tier and what they are responsible for. This internal understanding stops the dreaded "hot potato" escalation—where a ticket gets bounced around, causing delays and making an already unhappy customer even more frustrated.
H3: Setting Realistic Service Level Agreements
The final piece of the puzzle is your Service Level Agreement (SLA). An SLA is more than just a policy; it's a promise. It clearly sets expectations for both your team and your customers about how quickly issues will be handled at every stage. In escalation management, SLAs are what drive accountability.
Your SLAs should define two key metrics for each support tier:
- Response Time: How quickly an agent must acknowledge the issue and let the customer know they're on it.
- Resolution Time: The maximum time allowed to actually solve the problem.
These timeframes need to be realistic and should change based on the issue's priority. A critical system-wide outage demands a much faster response than a minor bug with a simple workaround.
To help you visualize this, here's a sample table showing how tiers and SLAs can work together in a real-world scenario.
Sample Escalation Tiers and SLAs
| Support Tier | Responsibility | SLA (Response Time) | SLA (Resolution Time) |
|---|---|---|---|
| Tier 1 | Initial contact, basic troubleshooting | 1 hour | 24 hours |
| Tier 2 | Complex technical issues | 4 hours | 3 business days |
| Tier 3 | Critical bugs, server issues | 30 minutes | 8 hours |
This kind of structure creates a predictable, reliable system. When a Tier 1 agent escalates a problem, the SLA clock for Tier 2 immediately starts ticking, which creates urgency and clear ownership. This is how you build an escalation framework that doesn't just look good on paper but actually works when it matters most.
Turning Your Framework into Flawless Execution

A well-designed escalation framework is a great start, but it’s just a blueprint. The real magic happens when plans meet pressure. Turning your documented process into a smooth, real-world operation is all about turning your team from reactive firefighters into proactive problem-solvers.
This is where consistency, clear communication, and accountability truly matter. Without them, even the most detailed plan can fall apart during a real crisis. The goal is to make your escalation process a reliable, repeatable habit for every single person on your team.
Foster Crystal-Clear Communication
Communication is the absolute lifeblood of escalation management. Think about it: when a customer is already frustrated, the last thing they want is to feel like they’re being bounced around without anyone knowing what’s going on. Your agents need to master two types of communication: with the customer and with each other.
-
External Communication (With the Customer): Agents must project confidence and empathy. Instead of a cold, "I have to escalate this," try something like, "I understand how frustrating this is. I'm bringing in one of our technical specialists who has the right tools to get this fixed for you quickly." This simple shift reframes the handoff as a positive step toward a solution.
-
Internal Communication (Between Teams): The handoff between support tiers has to be seamless. The next agent in line should get a complete picture without ever having to ask the customer to repeat themselves—a classic source of frustration. In fact, Forbes reports that 96% of customers who have a bad experience will leave, and repeating information is a guaranteed bad experience.
Nailing both sides of communication ensures the customer feels cared for while your internal teams operate like a well-oiled machine.
Document Everything Meticulously
During a high-stakes escalation, thorough documentation is your best friend. This isn't about creating red tape; it's about building a single source of truth that anyone can step into and understand instantly. Every action, every conversation with the customer, and every diagnostic step needs to be logged in the ticket.
Rigorous documentation prevents knowledge gaps when an issue moves between shifts or support tiers. It ensures the Tier 3 engineer has the full context from Tier 1's initial conversation, saving valuable time and preventing missteps.
This habit is also the backbone of accountability. It creates a clear record of who did what and when, which is crucial for both resolving the current issue and analyzing it later. If you want to dive deeper into how structured processes boost efficiency, this guide on Document Workflow Management is a great resource.
Turn Every Escalation into a Learning Opportunity
The job isn't done just because the ticket is closed. The best support teams conduct post-incident reviews or root cause analyses for major or recurring escalations. The point isn't to assign blame, but to find ways to improve the entire system.
Start by asking these key questions:
- What was the true root cause of the problem? Was it a product bug, a gap in our training, or a confusing process?
- How could we have caught this earlier? Were there warning signs we missed along the way?
- What can we change to prevent this from happening again? The answer might be updating a knowledge base article, improving agent training, or flagging a bug for the development team.
By consistently reviewing what went wrong, you build a culture of continuous improvement. Each escalation becomes a valuable lesson that strengthens your products, processes, and people, ultimately leading to fewer crises and happier customers.
Using AI to Predict and Prevent Escalations
https://www.youtube.com/embed/TjB9tsdDFuk
Traditional escalation management is reactive. A problem pops up, a customer gets frustrated, and the team scrambles to put out the fire. But what if you could see the smoke before the flames? That’s exactly what artificial intelligence is bringing to the world of customer support.
AI is helping teams shift from firefighting to fire prevention. It works like an early warning system, catching the subtle signs of a brewing problem long before a customer feels the need to demand a manager. This lets your team step in early, resolving issues at a lower-cost, lower-stress tier.
How AI Senses Customer Frustration
At its heart, predictive AI in customer support is all about pattern recognition. It digs through data from incoming tickets, live chats, and emails, looking for clues that a human might easily miss. It's not just scanning for keywords; it's reading the room.
Modern tools use sentiment analysis to get a read on a customer's emotional state. It can detect sarcasm, urgency, and rising frustration in the language used, flagging a conversation for review even if the customer hasn't explicitly complained. For example, a ticket with phrases like, "I’ve already explained this twice," or "this is getting ridiculous" can be automatically bumped up the priority list.
A significant trend in escalation management is the adoption of artificial intelligence (AI) to automate and optimize the process. AI-powered tools analyze vast amounts of data to identify patterns and predict potential escalation scenarios, allowing organizations to resolve issues at an early stage. Discover more insights about how AI optimizes IT services on Meegle.com.
Intelligent Automation for Smarter Routing
Beyond just predicting trouble, AI is also brilliant at intelligent automation. When an issue does need to be escalated, AI can make sure it gets to the right person, right away. No more manual hand-offs or agents trying to figure out who knows what.
Here’s how it typically works:
- Content Analysis: The AI instantly categorizes a ticket based on its topic and technical nature, like "billing issue," "API bug," or "login failure."
- Skills-Based Routing: It then cross-references that category with your team's skills, sending the ticket to the agent or team best equipped to handle it.
This automated routing slashes the time a ticket spends bouncing around in a queue. A complex database issue gets routed directly to a Tier 3 engineer, skipping the intermediate steps and speeding up the whole resolution process. To see how this works in a real-world flow, take a look at this detailed escalation process example.
AI as a Co-pilot, Not a Replacement
It's easy to think of AI as something that will replace support agents, but that’s not the goal. The real value is in having AI work alongside your team, augmenting their skills. Think of it as a co-pilot that manages the repetitive, data-heavy tasks, freeing up your experts to do what they do best.
By flagging at-risk tickets and automating routing, AI gives your team more time for deep problem-solving and building real relationships with customers. You can explore various AI tools and platforms to get a better sense of what's possible. The end game is to combine the speed and efficiency of technology with the empathy and critical thinking of your people. That's how you build a truly effective escalation management system.
Measuring What Matters in Escalation Management
It’s one thing to have a solid escalation framework on paper, but how do you know if it’s actually working in the real world? The old saying holds true: you can't improve what you don't measure. Tracking the right data is what turns your escalation process from a static set of rules into a dynamic system that learns and gets better over time.
This isn’t about getting lost in spreadsheets. It’s about picking a handful of key performance indicators (KPIs) that tell a clear story about your team's performance, the efficiency of your process, and ultimately, the experience you're giving customers. These numbers are the vital signs of your support operation.
Core Metrics for Escalation Health
To get the full picture, you need to look at more than just one number. A few core metrics, when viewed together, can show you exactly where things are running smoothly and where bottlenecks are starting to form. Think of these as the diagnostic tools for your entire process.
Start by tracking these fundamental KPIs:
- Escalation Rate: This is simply the percentage of total tickets that get escalated. Is it high? Is it climbing? That could be a sign that your front-line agents need more training or better tools to solve problems on their own.
- First Contact Resolution (FCR): What percentage of issues get solved by the very first agent, with no handoffs needed? A high FCR points to an empowered and well-equipped front-line team—the foundation of great escalation management.
- Mean Time to Resolution (MTTR) by Tier: This is the average time it takes to close a ticket at each support level. If your MTTR is suddenly spiking at Tier 2, for example, it might mean that team is understaffed or dealing with a new wave of complex problems.
These metrics give you a great high-level overview. But the real magic happens when you start digging into what they’re telling you.
Turning Numbers into Actionable Insights
Data is only valuable when it leads to action. The goal here is to spot trends and patterns that uncover the root cause of escalations, letting you fix the process, not just the individual ticket.
The best support teams use metrics to find opportunities, not to assign blame. A high escalation rate isn't a failure; it’s a signpost pointing to a specific training need or a gap in your knowledge base.
For example, if you see that escalations about "billing errors" have doubled this month, you can get ahead of the curve. You can create new training modules or a self-service guide to address that exact issue. This data-driven approach helps you prevent problems before they overwhelm your team.
You should also keep a close eye on customer satisfaction (CSAT) scores for escalated tickets specifically. If customers are consistently unhappy even after an escalation, that's a huge red flag. It might mean your handoff process is clunky or that your higher-tier agents need a refresher on empathetic communication. By tracking a broad range of customer service quality metrics, you get a much clearer view of your overall performance. Combining these operational stats with customer feedback creates a powerful loop that fuels constant improvement.
Common Questions About Escalation Management
Even with the best-laid plans, real-world customer support always throws a few curveballs. Your team will inevitably run into tricky situations that don't neatly fit into a playbook. Let's tackle some of the most common questions that pop up on the support floor.
Think of this as the practical advice you need to turn your escalation theory into effective, everyday practice.
Hierarchical vs. Functional Escalations
One of the first things people get tangled up on is the difference between hierarchical and functional escalations. They both involve handing off a ticket, but they solve completely different problems.
-
Functional Escalation: This is all about expertise. Imagine a front-line agent gets a technical question about a bug deep in your software's code. They don't have the answer, but the engineering team does. The agent escalates the ticket sideways to the engineers. It's not about seniority; it's about finding the person with the right specialized skills for the job.
-
Hierarchical Escalation: This is the classic "let me speak to your manager" scenario. A ticket moves up the chain of command. This usually happens when a service level agreement (SLA) has been breached, a customer is extremely dissatisfied, or the issue involves a high-value client. The ticket goes to a team lead or manager who has more authority to approve a refund, offer a credit, or make a strategic decision.
Preventing Premature Escalations
So, how do you stop agents from hitting the escalate button too soon? It’s a common frustration, but the root cause is often a lack of empowerment, not a lack of effort.
The answer lies in a mix of solid training and genuine trust. Your agents need a comprehensive knowledge base they can rely on and clear guidelines on what they're expected to handle themselves. It also helps to have a quality assurance (QA) process where you review escalations. Use those reviews as coaching moments to give constructive feedback and, just as importantly, praise agents who successfully resolve tough issues on their own.
The goal is to build an environment where agents feel confident tackling complex problems, not scared of making a mistake. Empowerment is what really drives down unnecessary escalations and improves your First Contact Resolution rate.
Improving Your Current Process
If you know your current escalation process is broken, where do you start fixing it? The first step is simple but powerful: map your current process exactly as it happens today.
Don't just pull up the official handbook. Sit down with your agents and team leads. Ask them to walk you through what really happens when a ticket gets escalated. This will instantly show you where the communication gaps, bottlenecks, and biggest frustrations are. Once you have that honest picture, you’ll know exactly which fires to put out first.
And what about that customer who immediately demands to speak to a manager? The key is empathy and control. Acknowledge their frustration, then calmly explain that to get them to the right person who can actually solve their problem, you first need to understand a few key details. You’re not putting up a roadblock; you’re clearing the fastest path to a solution.
Ready to stop escalations before they start? Screendesk replaces long text explanations with clear video recordings and live video chat, letting your team see and solve issues in minutes. See how you can improve resolution times and customer satisfaction.